

Next: Layout Specifications Up: No Title Previous: Abstract
Next: Layout Specifications
Up: No Title
Previous: Abstract
Although programming has mostly been done in textual terms, users have always had a notion of visualizing their programs. Users entered programs as lines of text, but soon thereafter they began to use indentation and comments for separating or emphasizing particular program parts. They developed tools for pretty-printing and formatting source code. Moreover, modern programming environments offer debugging tools such as browsers and inspectors, which provide users with views of program structure and execution states. But these views display their information more textually than visually (pictorially). A further shortcoming of current environments is their lack of offering program designers adequate tools for visualizing and animating programs. We propose a classification scheme which distinguishes visualization by two kinds of strategies: structural and conceptual visualization.
Structural visualization uses program and data structures to generate relevant geometrical information for graphic substrates. An important problem related to this kind of visualization is that conceptual information about data can only indirectly be derived (e.g. from naming of identifiers). A very common approach to structural visualization is to guide the visualization process by underlying programming styles or computational models. Many approaches to visualizing imperative systems use flow charts or Nassi-Shneiderman diagrams. The Transparent Prolog Machine [3] is an example for relational or logic systems. A more radical approach is presented by Pictorial Janus [4]. It defines complete visualizations of concurrent logic programs and captures static as well as dynamic information about these programs. Furthermore, there exist many approaches to visualizing data flow in functional systems. One of the early systems was PICT/D [5]. Examples of newer systems are ConMan [6] and Prograph [7]. An overview of data-flow environments can be found elsewhere [8]. Regarding object-oriented systems a diagramming approach to tracing message passing [9] has been implemented as an extension of a Smalltalk-80 debugger. GraphTrace [10] is also intended for understanding behavior of objects. It provides graphical traces of program executions. All these approaches are primarily focused on the structure of computations. They offer only poor support for visualizing concepts of domains that are represented or modeled by programs. We use the notion of ``conceptual visualizations'' for advanced graphics reflecting domain concepts. Conceptual visualizations of programs are mostly hand-coded. This hand-design is basically caused by the fundamental problem that geometrical and graphical information necessary to create suitable visualizations cannot automatically be derived from corresponding data.
In this contribution we discuss schemes for (aesthetically) laying out combinations of graphical objects. With respect to forms-oriented user interfaces, allocation of space and positioning of objects is mostly constrained by the space globally available. Graphical interfaces usually also add local constraints. A typical application is a browser generating net-like representations of rule sets, classes, or objects. The spatial allocation of nodes may depend on adjoining nodes or the topology of edges (e.g. in order to avoid line crossing or long winding paths). This problem is (at least partially) addressed by many constraint-oriented systems. ThingLab I [11] and II [12] are examples for describing layout and form of graphical objects with constraints. Garnet [13] is also a toolkit using techniques such as constraints and active values.
In contrast to the constraint-oriented approaches mentioned above, we decided to
provide a simpler but more compact and predictable notation for specifying
layout. In the following we describe an approach to specifying layout of
graphical objects, which is based upon TeX-like layout specifications. Users can
define layout descriptions declaratively. However, layout specifications can
also be computed by higher-level modules, e.g. using pattern matching
techniques. Furthermore, our approach has the advantage of requiring only
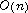 steps, be
steps, be
 the number of layout elements. Thus, our
algorithm has a computational complexity of
the number of layout elements. Thus, our
algorithm has a computational complexity of
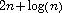 .
.
The second topic discussed in this paper concerns the connection between application and visualization. We show how the CLOS Meta-Object Protocol might be used to design a component that links application to visualization objects and vice versa.
Throughout this paper we present several examples describing our layout notation and meta-level techniques. Since our implementation is based on a Macintosh Lisp environment, these examples are given in (simplified) Lisp code and assume a basic knowledge of Lisp and CLOS.
The remainder of this paper is structured as follows. Section 2 introduces our declarative layout specifications and demonstrates a CLOS class browser and inspector, which serve as examples for the flexibility of our approach. Section 3 introduces user-defined layout schemes and mechanisms for specifying references (local dependencies) between graphical objects. Section 4 explains our basic layout algorithm in more detail. The second part of our paper begins with Section 5 and discusses how to use the CLOS meta-object protocol for program visualization. It demonstrates some of these considerations by using a simple constraint system as example domain. Section 6 summarizes the current status of our implementation. Section 7 compares our approach with related work concerning layout descriptions. This paper concludes with a summary and a discussion of future work.
Next: Layout Specifications
Up: No Title
Previous: Abstract